Kita akan melihat ringkasan data secara sekilas. Berikut adalah ringkasan data income yang terdiri atas variabel: income dan happiness.
summary(income.data)
X income happiness
Min. : 1.0 Min. :1.506 Min. :0.266
1st Qu.:125.2 1st Qu.:3.006 1st Qu.:2.266
Median :249.5 Median :4.424 Median :3.473
Mean :249.5 Mean :4.467 Mean :3.393
3rd Qu.:373.8 3rd Qu.:5.992 3rd Qu.:4.503
Max. :498.0 Max. :7.482 Max. :6.863
Ringkasan data tersebut menunjukkan dua variabel pendapatan dan kebahagiaan yang mencakup nilai minimum, maksimum, mean, median dan quartil. Informasi ini dapat digunakan untuk melihat karakteristik variabel.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
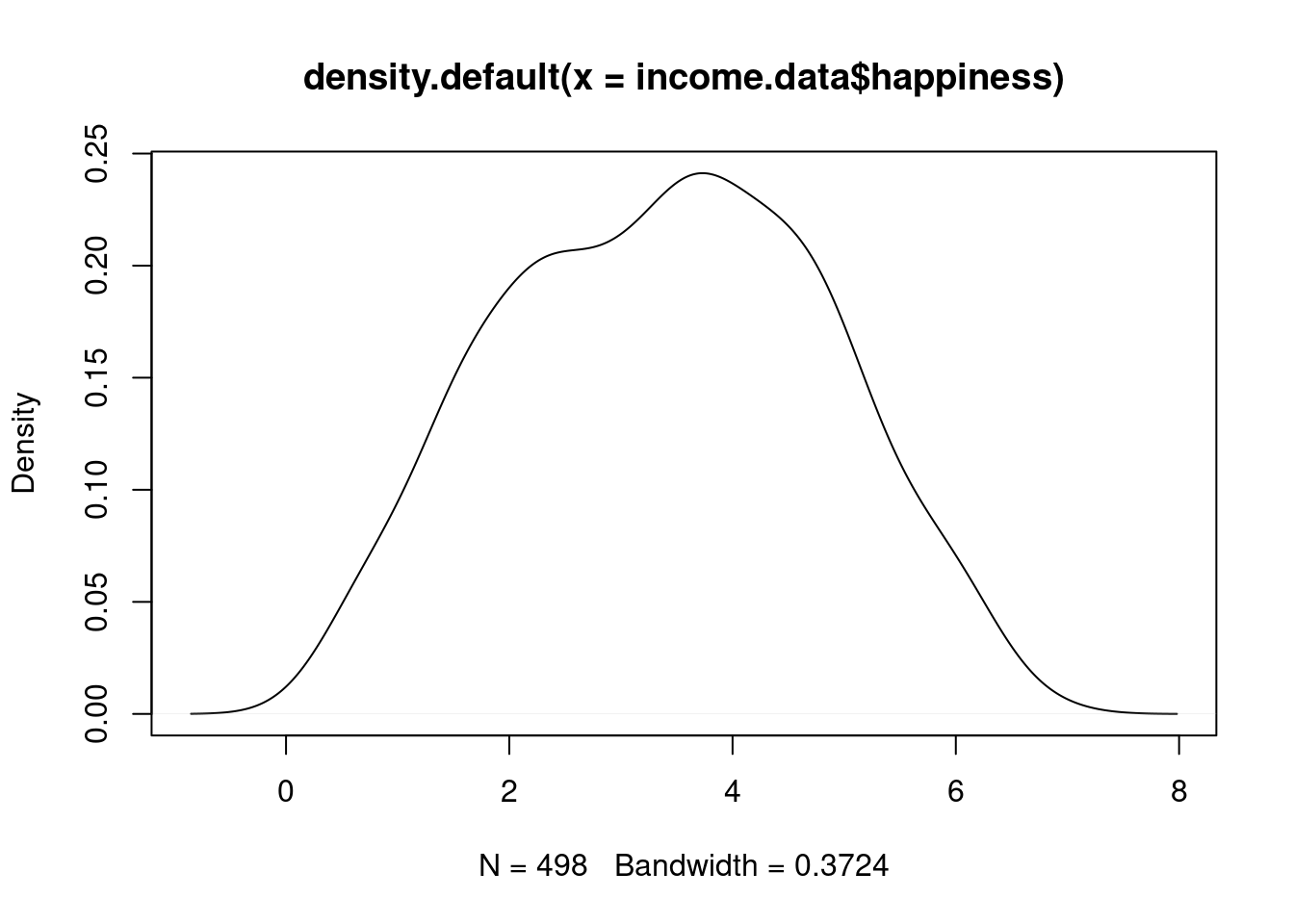
plot(density(income.data$happiness))
Grafik tersebut menunjukkan bahwa sebaran varibel cenderung membentuk kurva normal yang dapat dilihat dari density plot dan hal ini menggambarkan gejala normalitas.
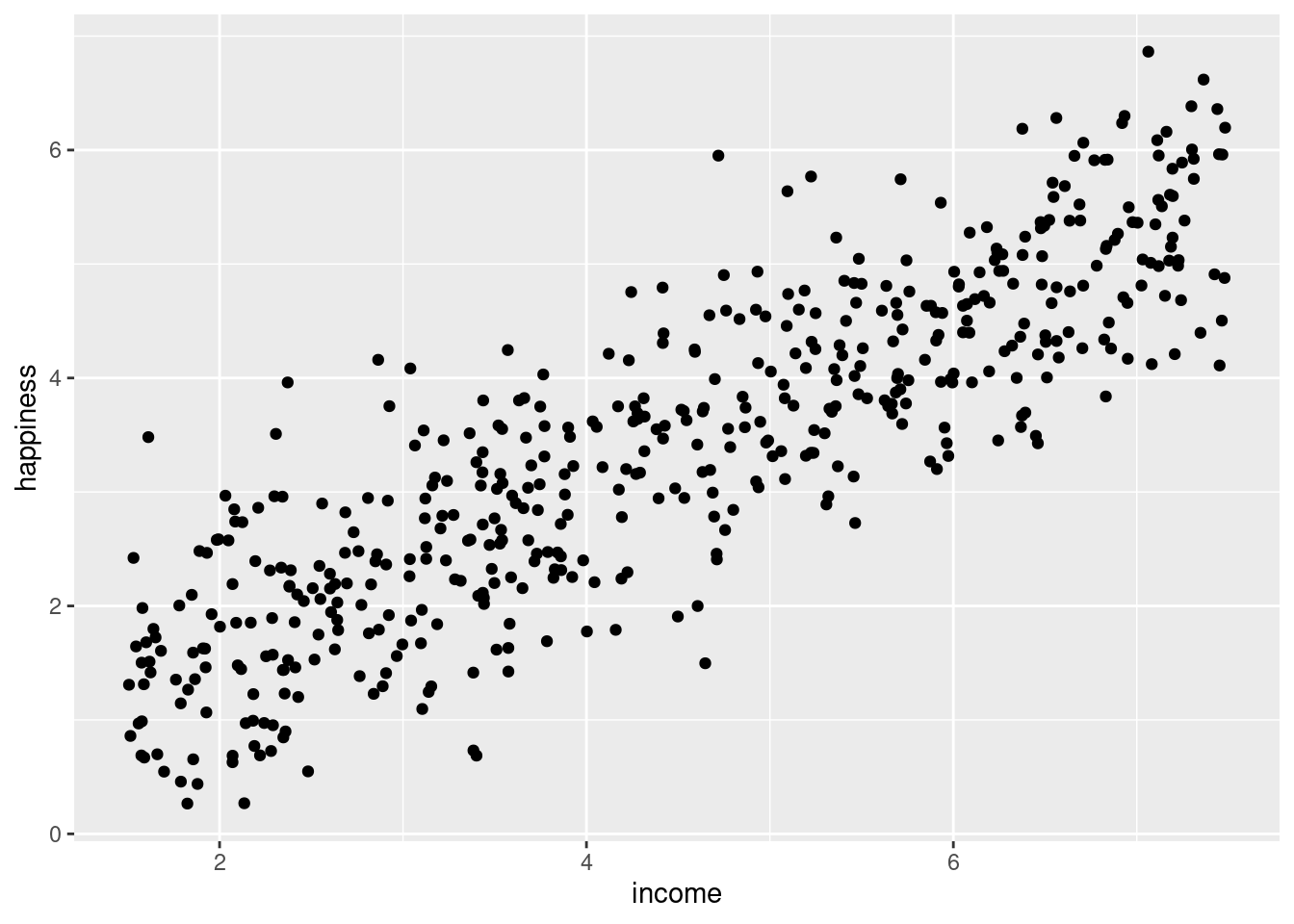
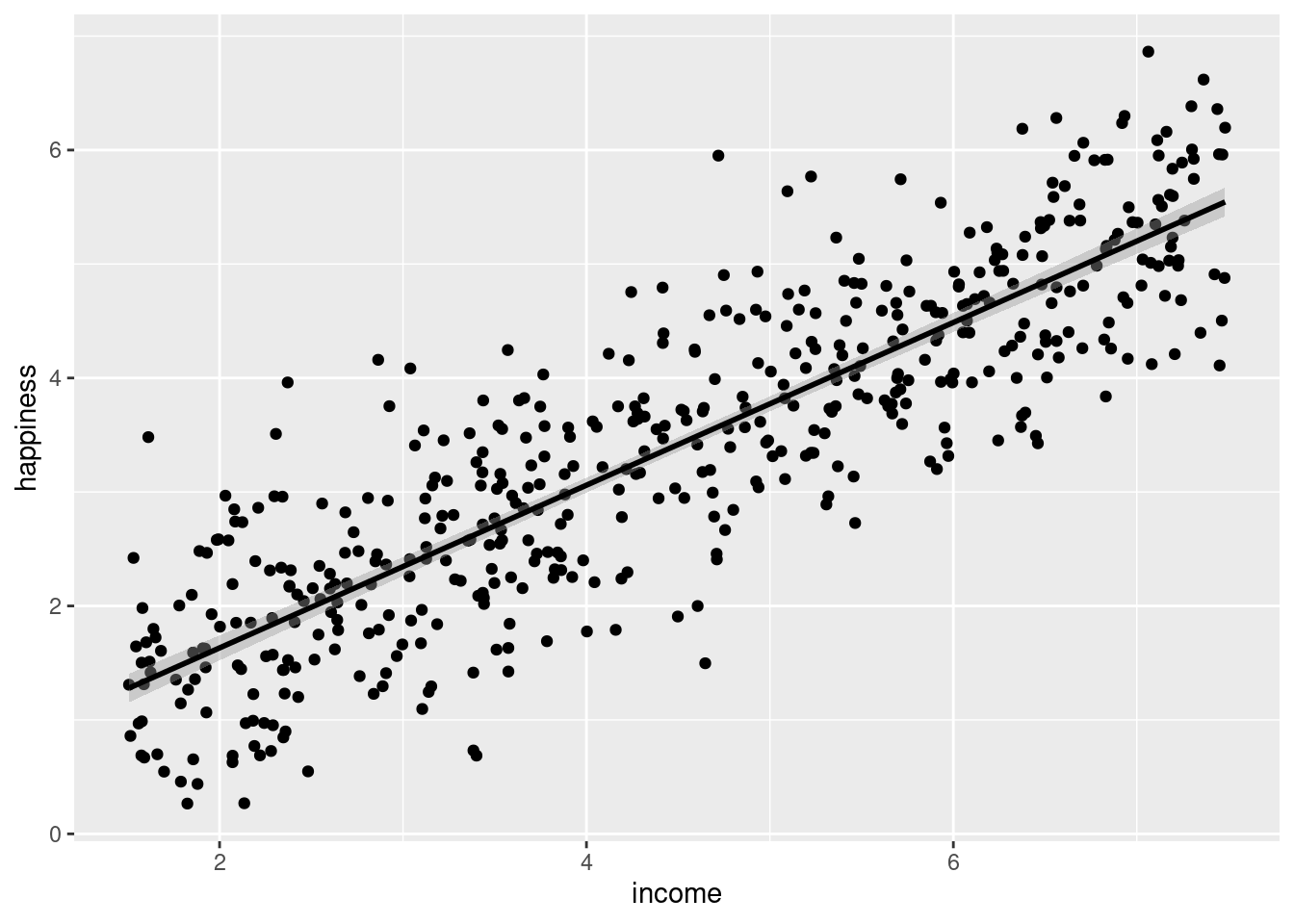
# Linearitasplot(happiness ~ income, data = income.data) # base R
Grafik tersebut menunjukkan hubungan yang linear antara income dan happiness. Kecenderungannya adalah semakin tinggi income seseoraang maka semakin tinggi pula skor happinessnya.
9.2 Model regresi linear sederhana
Mari kita lihat apakah ada hubungan linier antara pendapatan dan kebahagiaan dalam survei terhadap 500 orang dengan pendapatan mulai dari 15rb hingga 75rb, di mana kebahagiaan diukur pada skala 1 hingga 10.
Untuk melakukan analisis regresi linier sederhana dan memeriksa hasilnya, kita perlu menjalankan kode berikut. Baris pertama membuat model linier, dan baris kedua membuat ringkasan model:
# Model regresi sederhana: pendapatan and kebahagiaanincome.happiness.lm <-lm(happiness ~ income, data = income.data)summary(income.happiness.lm)
Call:
lm(formula = happiness ~ income, data = income.data)
Residuals:
Min 1Q Median 3Q Max
-2.02479 -0.48526 0.04078 0.45898 2.37805
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.20427 0.08884 2.299 0.0219 *
income 0.71383 0.01854 38.505 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.7181 on 496 degrees of freedom
Multiple R-squared: 0.7493, Adjusted R-squared: 0.7488
F-statistic: 1483 on 1 and 496 DF, p-value: < 2.2e-16
Bagian Koefisien menunjukkan:
Estimasi (Estimate) untuk parameter model – nilai perpotongan y (dalam hal ini 0,204) dan estimasi pengaruh pendapatan terhadap kebahagiaan (0,713).
Kesalahan standar dari nilai perkiraan (Kesalahan Std).
Uji statistik (nilai t, dalam hal ini t-statistik).
Nilai p ( Pr(>| t | ) ), atau probabilitas menemukan t-statistik yang diberikan jika hipotesis nol.
Tiga baris terakhir adalah diagnostik model – hal terpenting yang harus diperhatikan adalah nilai p (ini dia 2.2e-16, atau hampir nol), yang akan menunjukkan apakah model cocok dengan data.
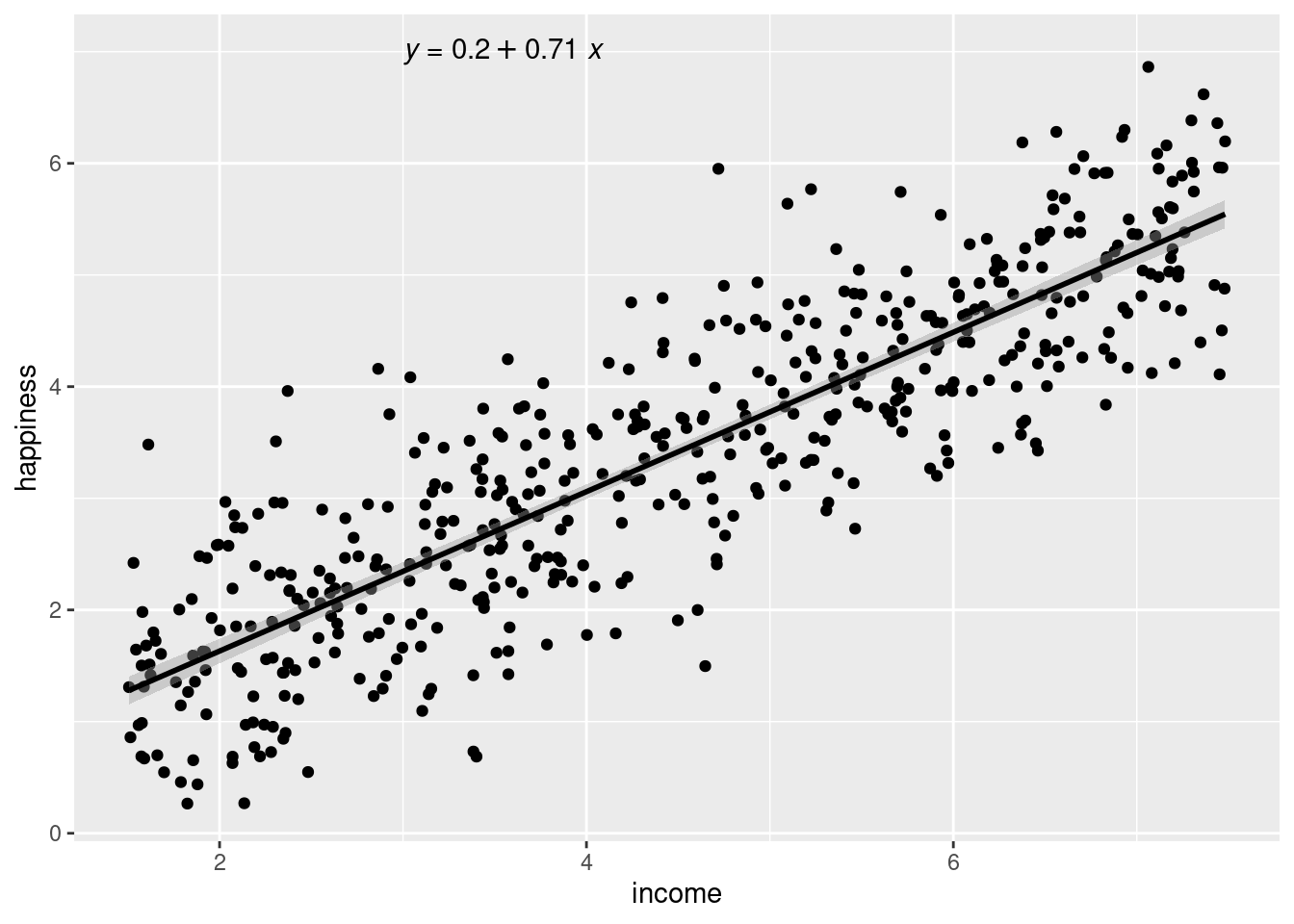
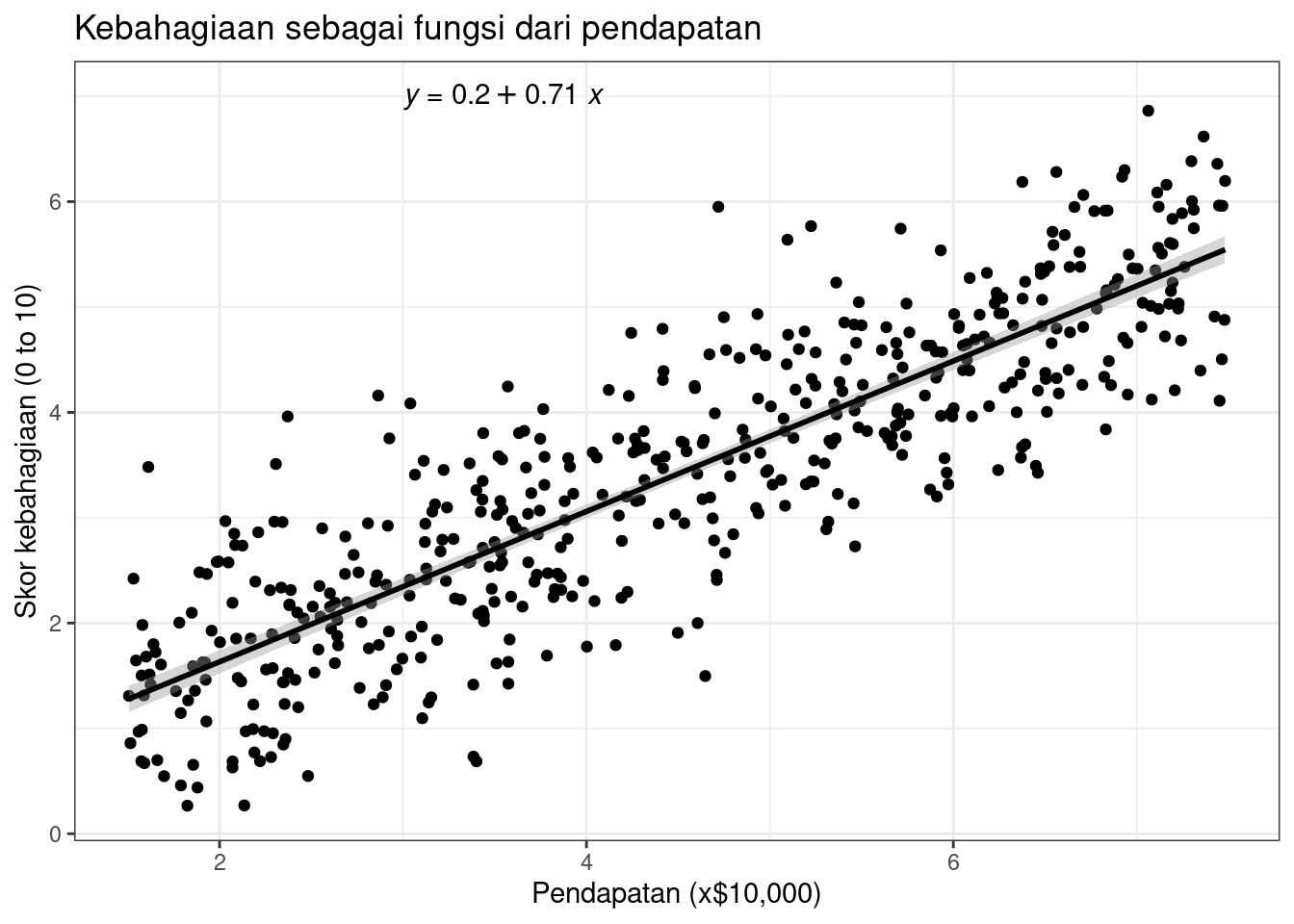
Hasil tersebut menunjukkan terdapat hubungan positif yang signifikan antara pendapatan dan kebahagiaan (p-value < 0,001), dengan peningkatan kebahagiaan sebesar 0,713 unit (+/- 0,01) untuk setiap peningkatan unit pendapatan.
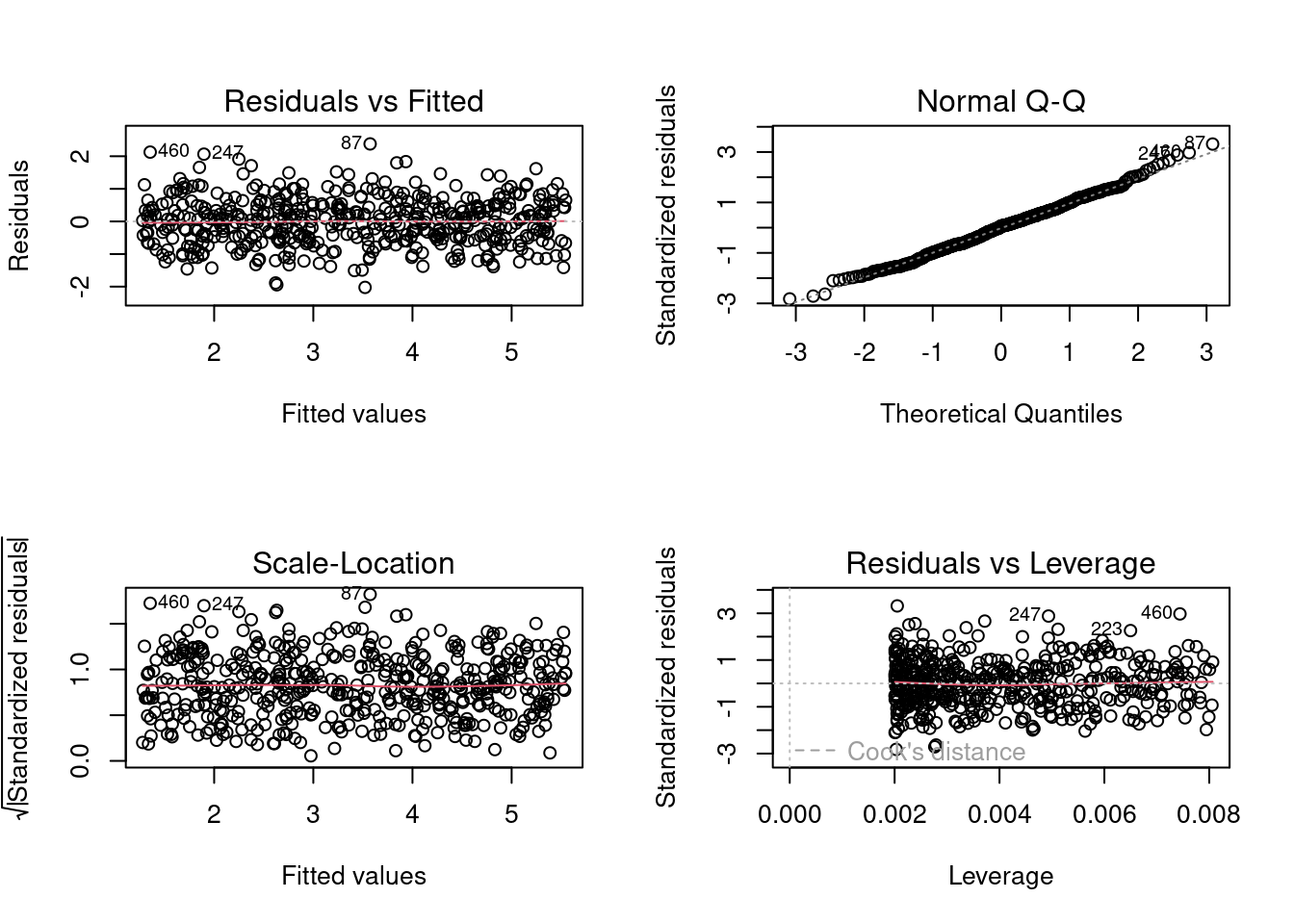
Plot yang perlu diperhatikan adalah plot kiri atas dan kiri bawah. Kiri atas adalah grafik residu vs nilai yang difitkan, sedangkan di kiri bawah adalah residu standar pada sumbu Y. Jika sama sekali tidak ada heteroskedastisitas, maka nampak distribusi titik yang benar-benar acak dan merata di seluruh rentang sumbu X dan garis merah datar.
# Visualiasasi regresi# Membuat plot korelasiincome.graph<-ggplot(income.data, aes(x=income, y=happiness))+geom_point()income.graph
# Menamabah garis regresi linearincome.graph <- income.graph +geom_smooth(method="lm", col="black")income.graph
# Menyiapkan grafik siap untuk pubklikasiincome.graph +theme_bw() +labs(title ="Kebahagiaan sebagai fungsi dari pendapatan",x ="Pendapatan (x$10,000)",y ="Skor kebahagiaan (0 to 10)")
`geom_smooth()` using formula = 'y ~ x'
9.3 Melaporkan hasil regresi linier sederhana
Berdasarkan analisis di atas, ada hubungan yang signifikan antara pendapatan dan kebahagiaan (p <0,001, R2 = 0,73 ± 0,0193), dengan peningkatan 0,73 unit dalam kebahagiaan untuk setiap kenaikan pendapatan $10.000.
9.4 Regresi berganda
summary(heart.data)
X biking smoking heart.disease
Min. : 1.0 Min. : 1.119 Min. : 0.5259 Min. : 0.5519
1st Qu.:125.2 1st Qu.:20.205 1st Qu.: 8.2798 1st Qu.: 6.5137
Median :249.5 Median :35.824 Median :15.8146 Median :10.3853
Mean :249.5 Mean :37.788 Mean :15.4350 Mean :10.1745
3rd Qu.:373.8 3rd Qu.:57.853 3rd Qu.:22.5689 3rd Qu.:13.7240
Max. :498.0 Max. :74.907 Max. :29.9467 Max. :20.4535
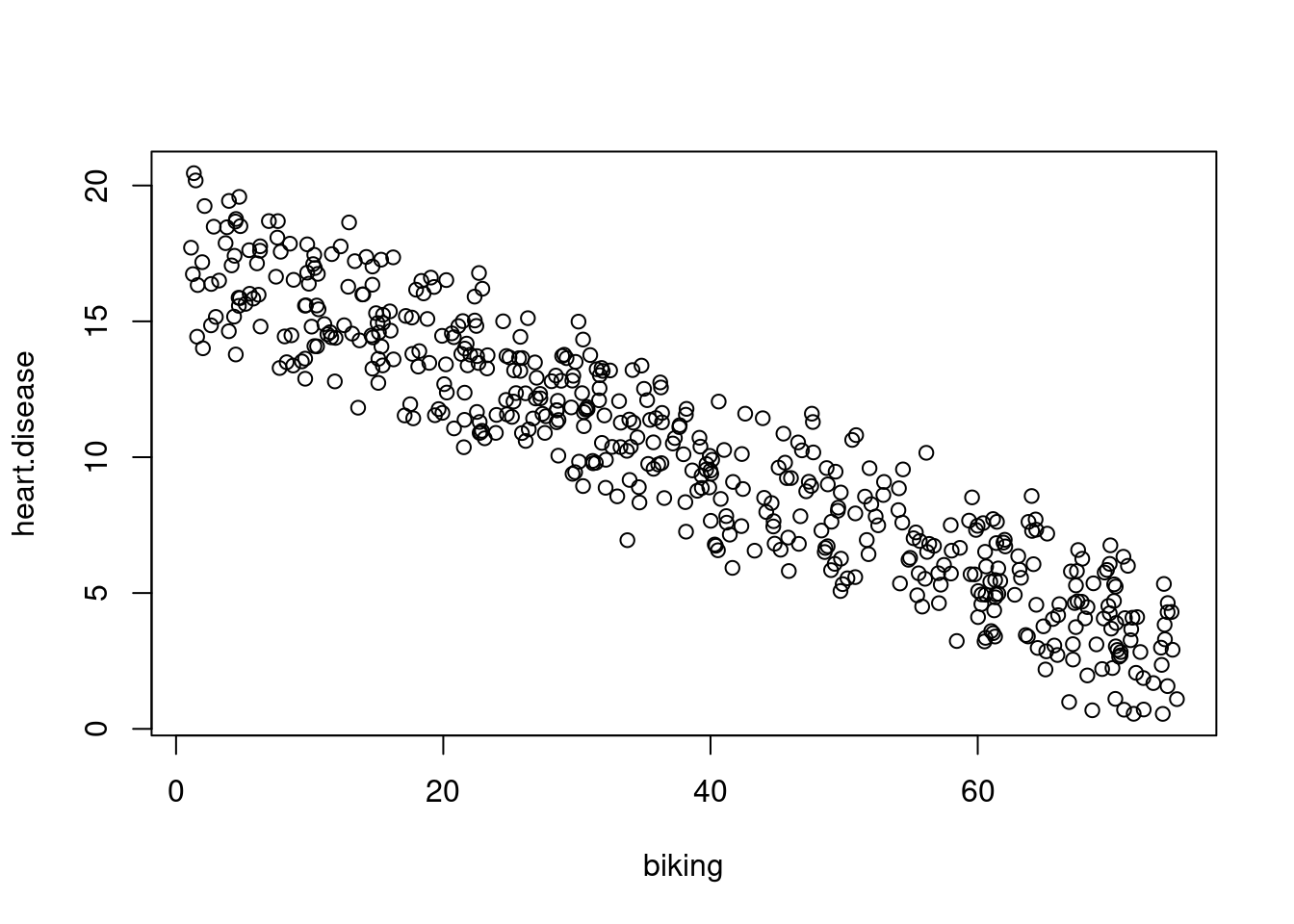
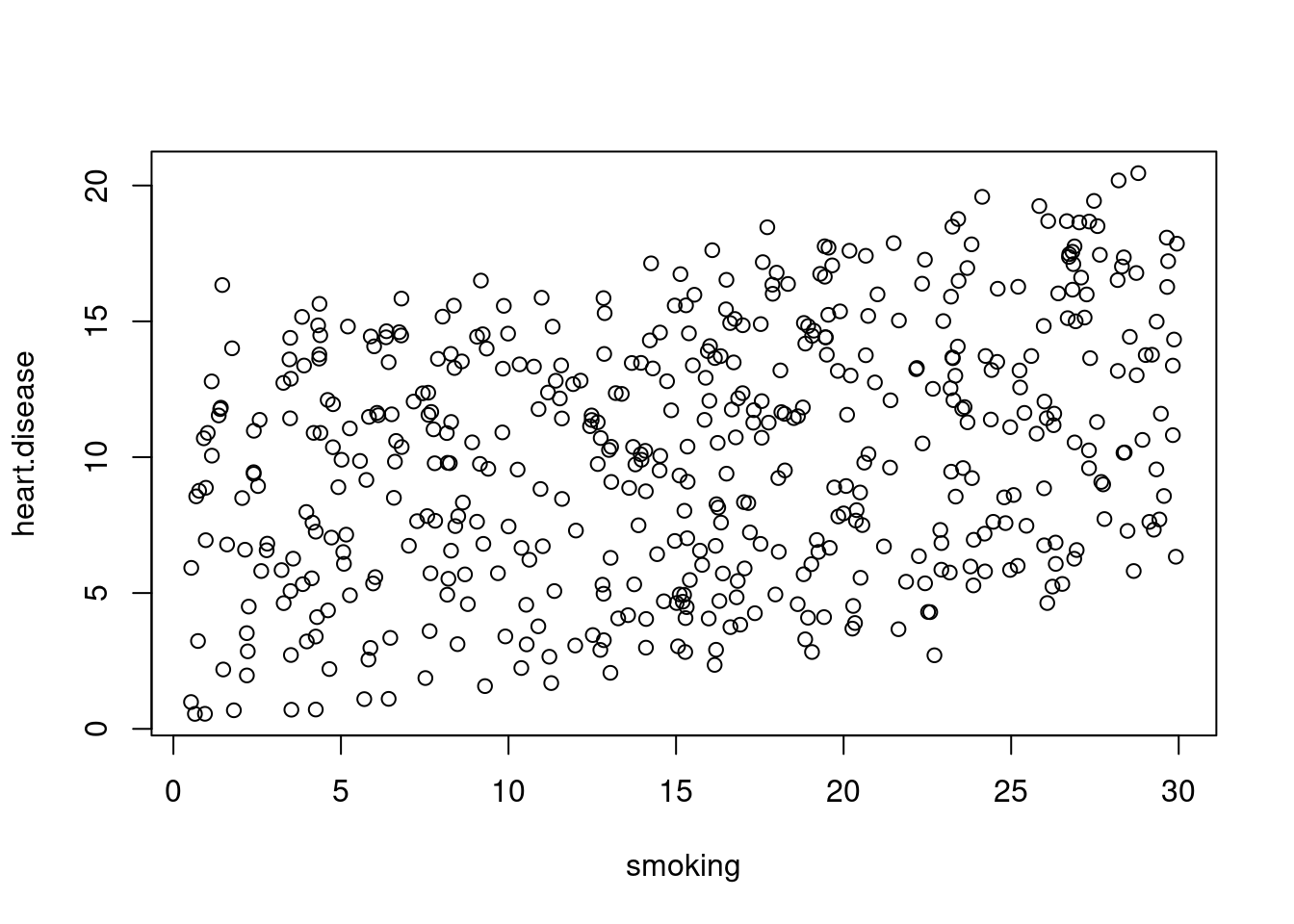
Mari kita lihat apakah ada hubungan linier antara bersepeda ke tempat kerja, merokok, dan penyakit jantung dalam survei imajiner di 500 kota. Tingkat bersepeda ke tempat kerja berkisar antara 1 sampai 75%, tingkat merokok antara 0,5 dan 30%, dan tingkat penyakit jantung antara 0,5% dan 20,5%.
Untuk menguji hubungan tersebut, pertama kita menyesuaikan model linier dengan penyakit jantung sebagai variabel terikat dan bersepeda dan merokok sebagai variabel bebas. Mari kita jalankan dua kode ini:
# Model regresi berganda: bersepeda, merokok, dan penyakit jantungheart.disease.lm<-lm(heart.disease ~ biking + smoking, data = heart.data)summary(heart.disease.lm)
Call:
lm(formula = heart.disease ~ biking + smoking, data = heart.data)
Residuals:
Min 1Q Median 3Q Max
-2.1789 -0.4463 0.0362 0.4422 1.9331
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 14.984658 0.080137 186.99 <2e-16 ***
biking -0.200133 0.001366 -146.53 <2e-16 ***
smoking 0.178334 0.003539 50.39 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.654 on 495 degrees of freedom
Multiple R-squared: 0.9796, Adjusted R-squared: 0.9795
F-statistic: 1.19e+04 on 2 and 495 DF, p-value: < 2.2e-16
9.6 Menafsirkan hasil
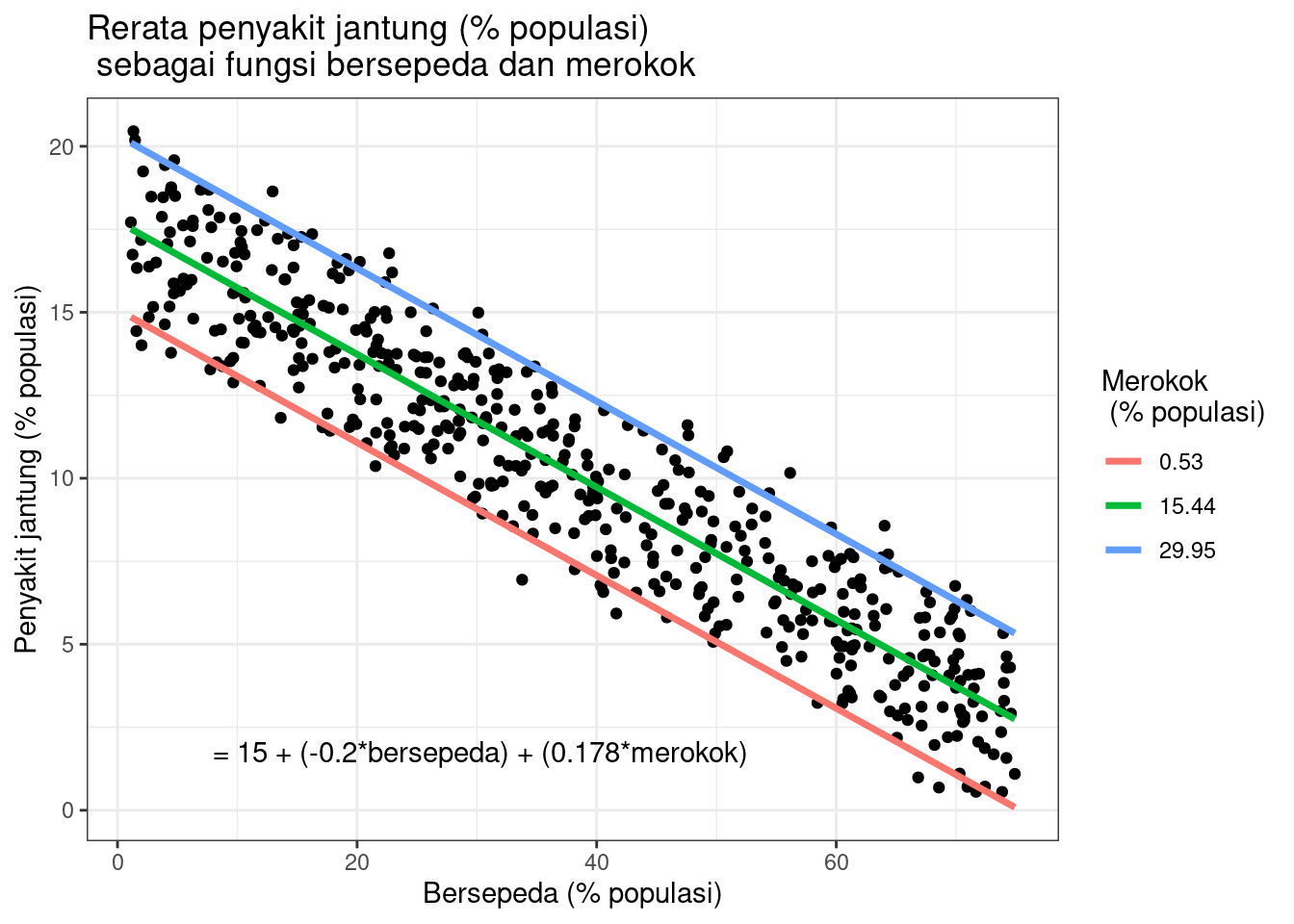
Perkiraan efek bersepeda pada penyakit jantung adalah -0,2, sedangkan perkiraan efek merokok adalah 0,178.
Hal ini menunjukkan bahwa untuk setiap 1% peningkatan bersepeda ke tempat kerja, terdapat korelasi penurunan 0,2% dalam penyakit jantung. Sementara itu, untuk setiap 1% peningkatan merokok, terjadi peningkatan 0,178% pada tingkat penyakit jantung.
Kesalahan standar untuk koefisien regresi ini sangat kecil, dan nilai t sangat besar (masing-masing -147 dan 50,4). Nilai-p mencerminkan kesalahan kecil ini dan statistik t yang besar. Untuk kedua parameter, kemungkinannya hampir nol bahwa efek ini disebabkan oleh kebetulan.
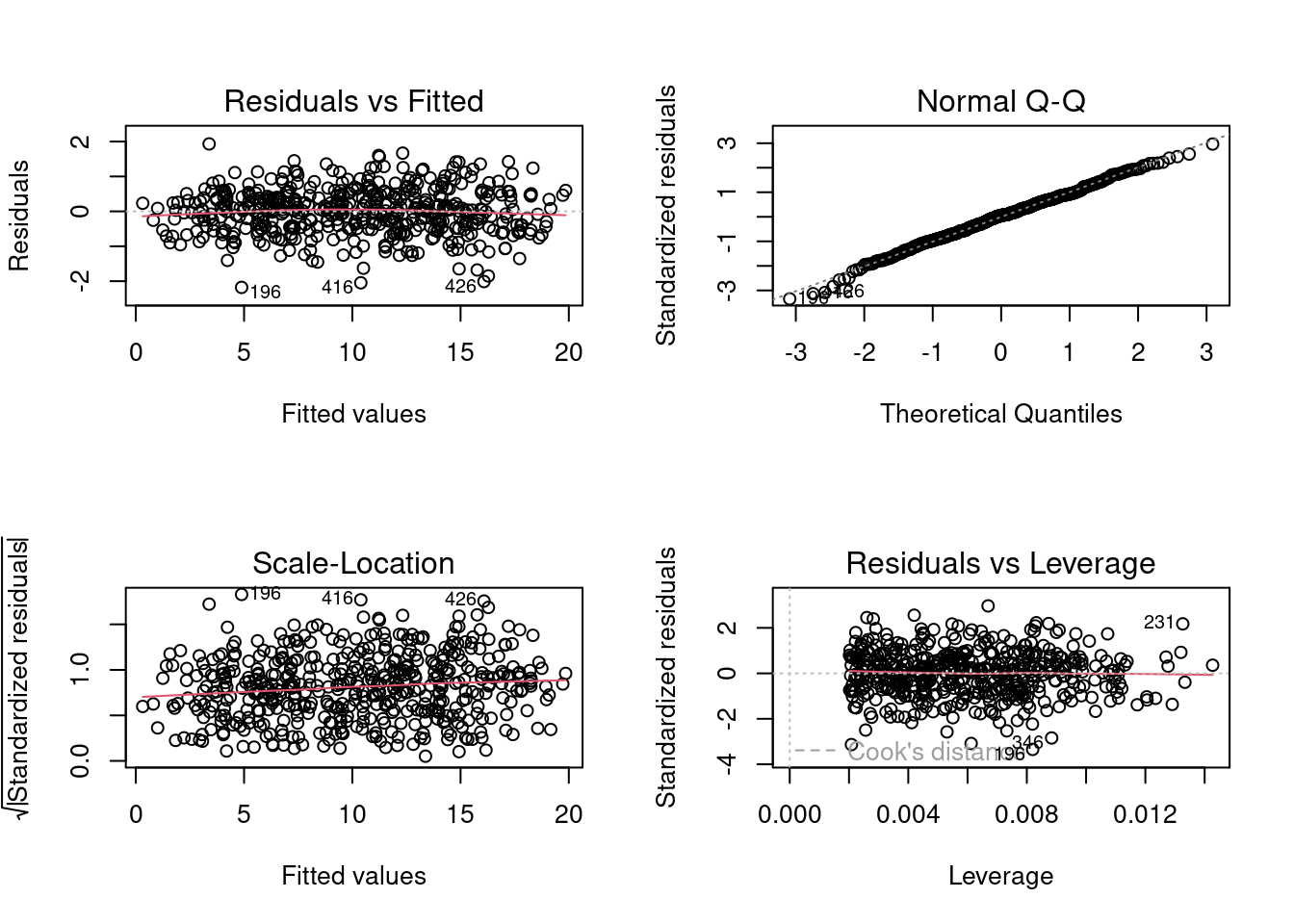
par(mfrow=c(2,2))plot(heart.disease.lm)
par(mfrow=c(1,1))
Berdasarkan hasil uji heteroskedaskisitas, maka hasil di atas memenuhi asumsi homoskedaskisitas.
9.7 Plotting regresi berganda
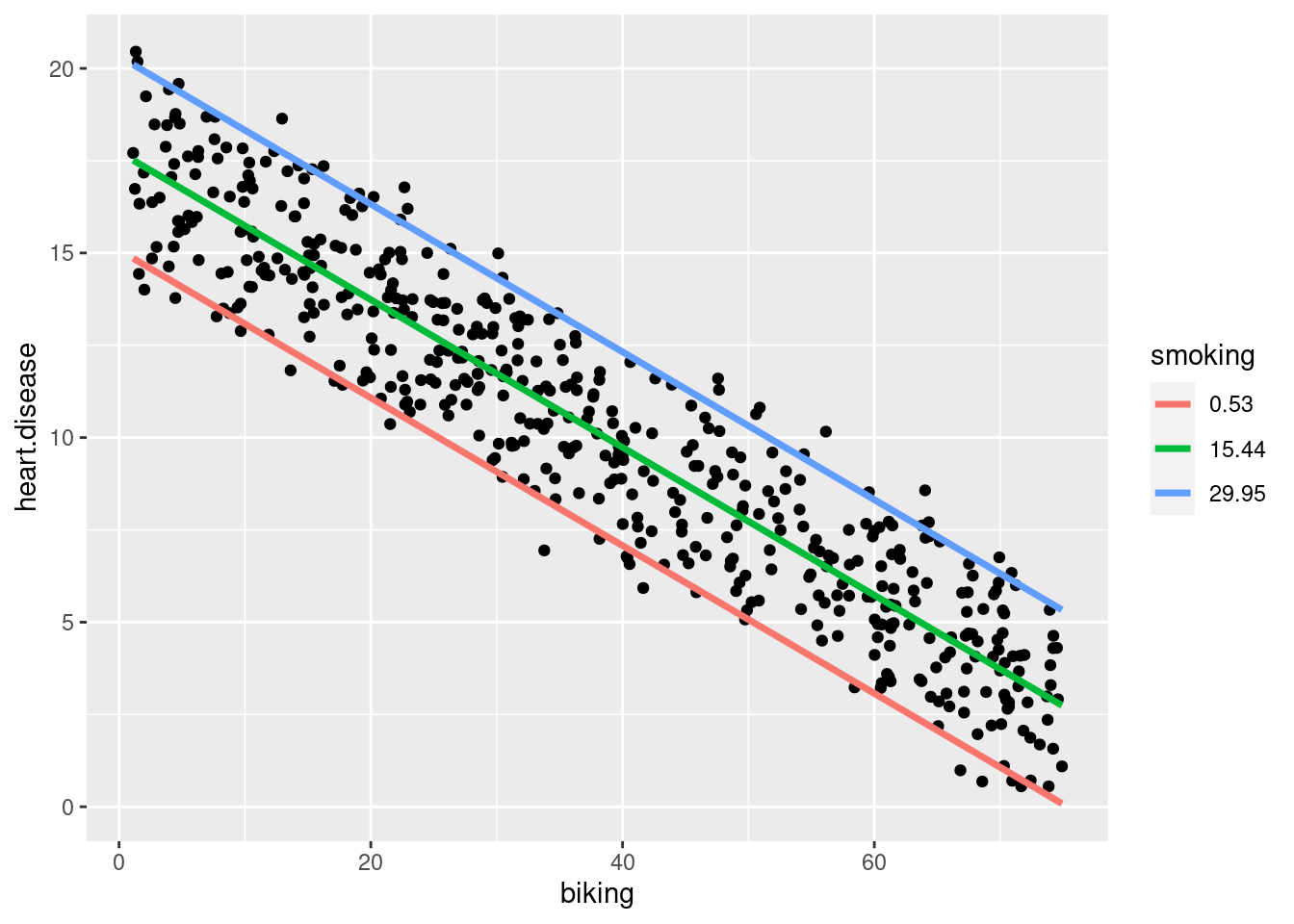
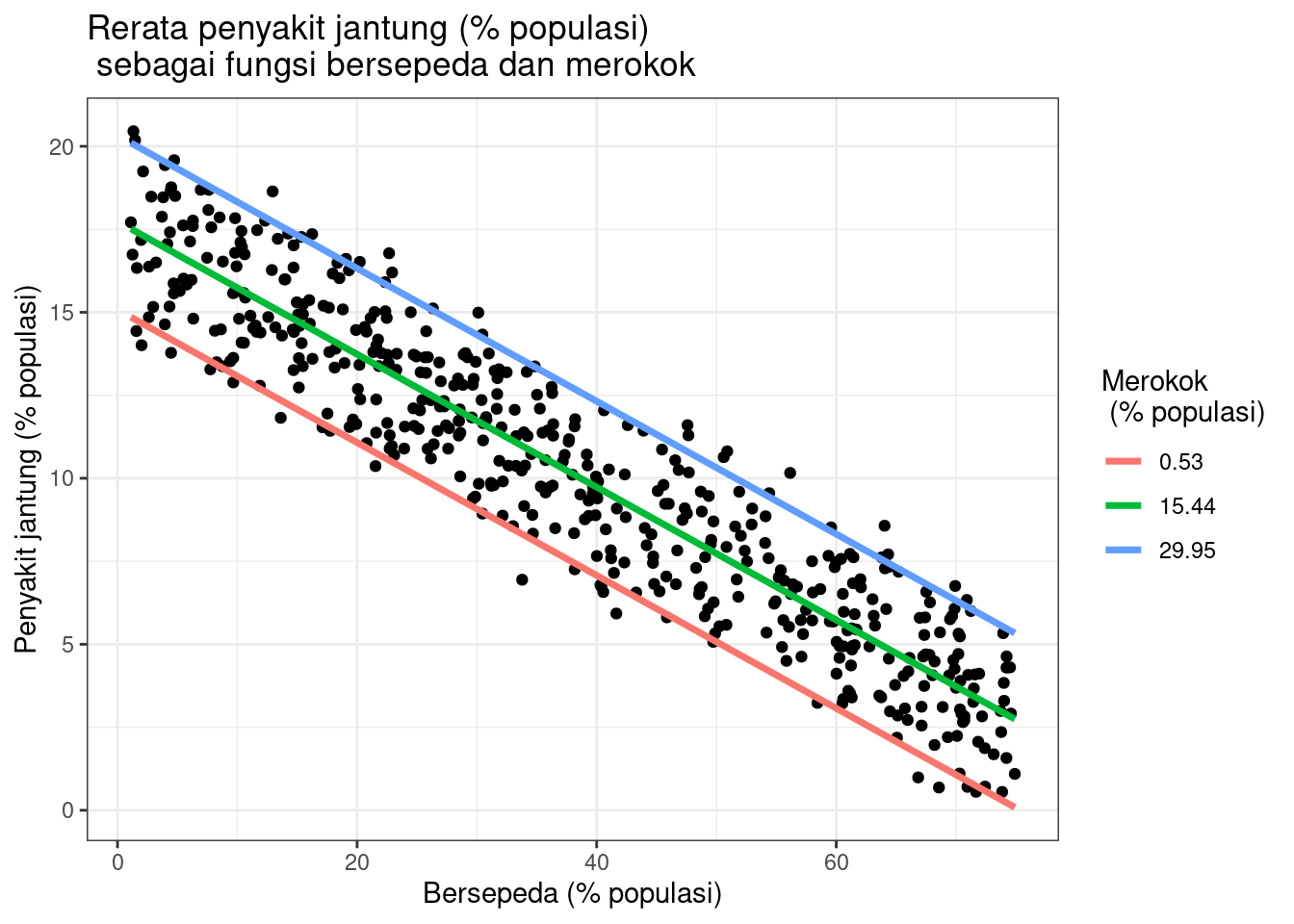
Gunakan fungsi expand.grid() untuk membuat kerangka data dengan parameter yang kita berikan. Buat urutan dari nilai terendah hingga tertinggi dari data bersepeda yang Anda amati; Pilih nilai minimum, rata-rata, dan maksimum merokok, untuk membuat 3 tingkat merokok untuk memprediksi tingkat penyakit jantung.
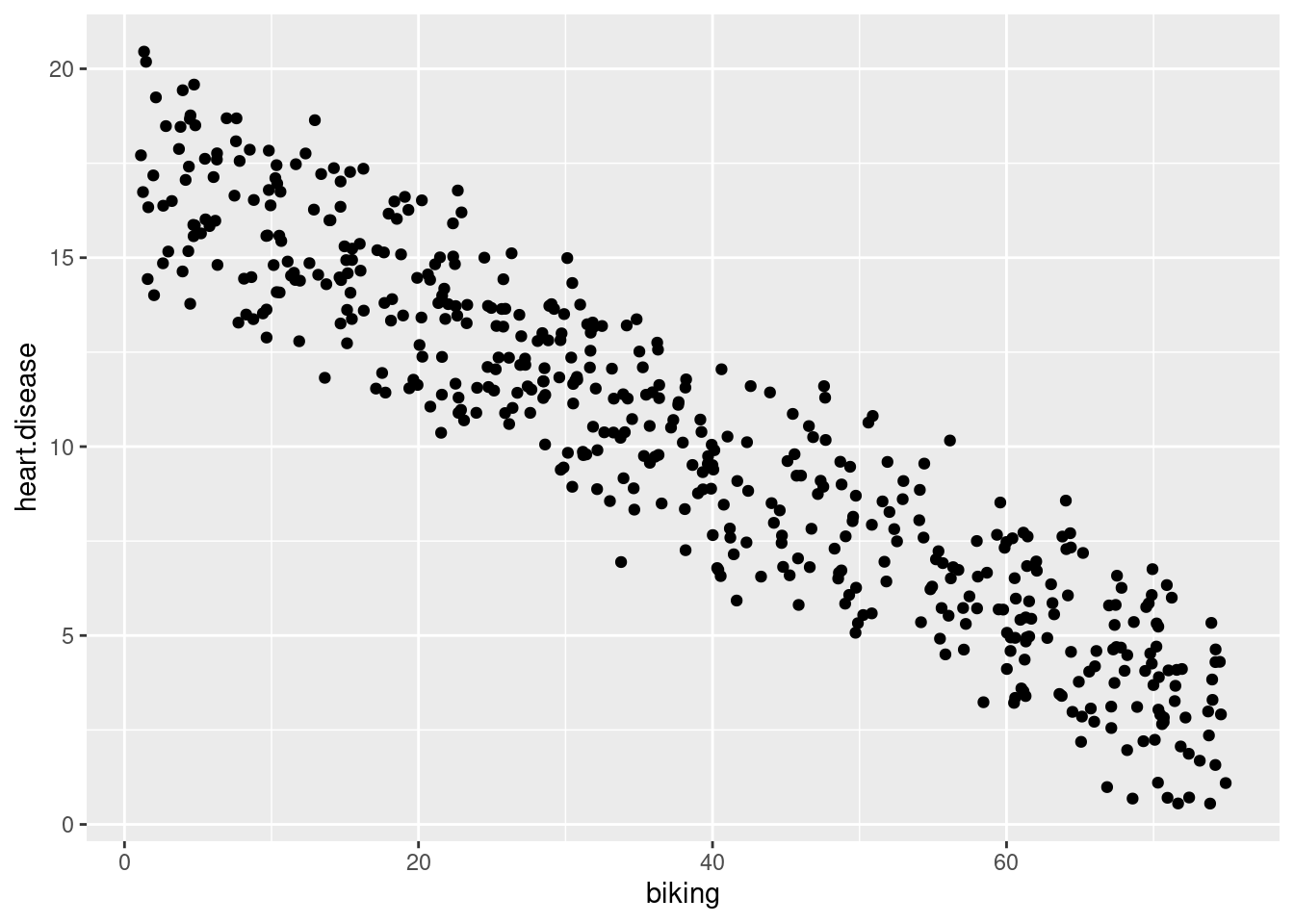
# Membuat dataframe yang digunakan untuk membuat plotplotting.data<-expand.grid(biking =seq(min(heart.data$biking), max(heart.data$biking), length.out=30),smoking=c(min(heart.data$smoking), mean(heart.data$smoking), max(heart.data$smoking)))# Prediksi nilai penyakit jantung berdasarkan model linier plotting.data$predicted.y <-predict.lm(heart.disease.lm, newdata=plotting.data)# Bulatkan angka merokok menjadi dua desimalplotting.data$smoking <-round(plotting.data$smoking, digits =2)# Ubah variabel 'merokok' menjadi faktorplotting.data$smoking <-as.factor(plotting.data$smoking)# Plot data asliheart.plot <-ggplot(heart.data, aes(x=biking, y=heart.disease)) +geom_point()heart.plot
Berdasarkan hasil analisis tersebut, terdapat hubungan yang signifikan antara frekuensi bersepeda ke tempat kerja dan frekuensi penyakit jantung serta frekuensi merokok dan frekuensi penyakit jantung (masing-masing p < 0 dan p <0,001). Secara spesifik analisis menunjukkan bahwa terdapat penurunan 0,2% (± 0,0014) dalam frekuensi penyakit jantung untuk setiap 1% peningkatan bersepeda, dan peningkatan 0,178% (± 0,0035) pada frekuensi penyakit jantung untuk setiap 1% peningkatan merokok.