library(ggplot2)
library(gcookbook)
library(plyr)
library(foreign)
library(lattice)5 Visualisasi Data
5.1 Pendahuluan
Memahami data merupakan salah satu kemampuan yang dibutuhkan untuk memahami statistika secara keseluruhan. Salah satu keunggulan yang dimiliki R adalah kemampuan untuk membuat grafik dan visualisasi data. R menyediakan visualisasi data dengan tingkat resolusi yang tinggi. Bab ini akan memberi penjelasan mengenai bentuk visualisasi data yang perlu digunakan dalam penelitian sosial. Selain itu, bab ini memberi contoh dan kode bagaiaman membuat plot data yang sedang diuji untuk memberi gambaran yang lebih menyeluruh mengenai data yang sedang diperiksa.
Bab ini membahas dan menjelaskan berbagai macam plot atau visualisasi data yang diperlukan dalam statistika, mulai dari bar plot, histogram, kernel density, box plot, violin plot, pie chart, scatter plot dan pembuatan peta. Pada masing-masing bentuk plot, akan dijelaskan pengertian plot, fungsi plot dan bagaimana mengimplementasikannya menggunakan R, serta penjelasan mengenai hasil plot yang diperoleh.
Dalam pemrograman R, ada beberapa package yang diperlukan untuk melakukan plot data dan visualisasi data dengan elegan adalah ggplot2, yang bisa digunakan dengan menuliskan kode berikut ini.
Setelah membuka package yang dibutuhkan, maka diperlukan melakukan pengesetan direktori agar semua langkah yang dikerjakan dapat tersimpan dalam satu direktori. Hal tersebut dapat dilakukan dengan langkah sebagai berikut.
5.2 Bar Plot
Bar plot atau plot batang adalah grafik yang menggunakan batang secara horizontal atau vertikal untuk menggambarkan perbandingan antara kategori. Salah satu sumbu grafik menunjukkan kategori tertentu yang dibandingkan dan sumbu lainnya merupakan nilai.
Contoh pertama akan menggunakan data yang tersimpan di package vcd. Plot pertama akan menggunakan barplot dari variabel counts merupakan gubahan dari dataset Arthritis dan variabel Improved. Barplot diperlukan sebagai perintah untuk dapat menjalankan program pembuatan diagram batang. Counts merupakan variabel yang akan diplot.
library(vcd)Loading required package: gridcounts <- table(Arthritis$Improved)
counts
None Some Marked
42 14 28 barplot(counts,
main="Bar Plot Sederhana",
xlab="Pengembangan", ylab="Frekuensi")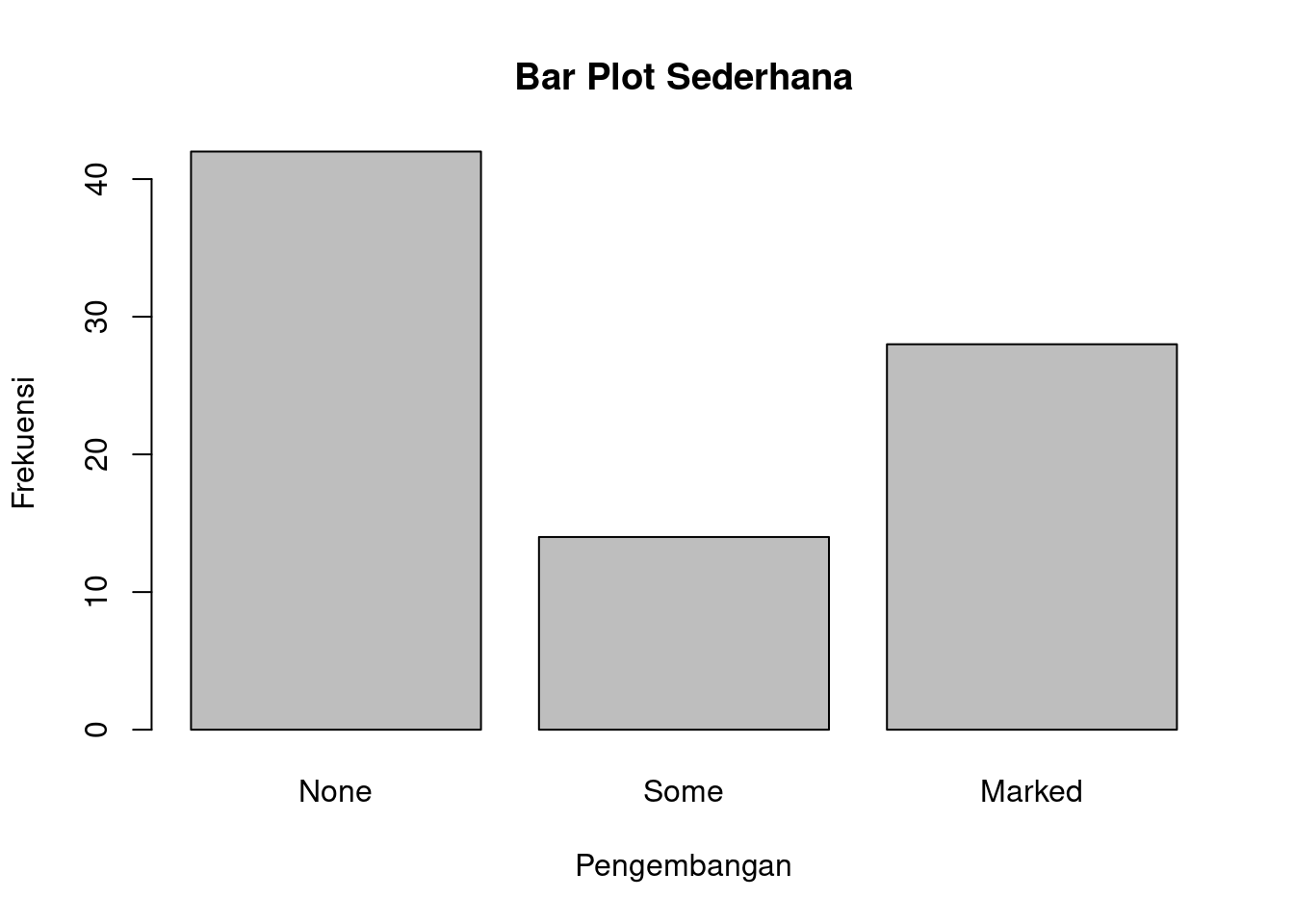
Perintah berikut ini merupakan kelanjutan dari perintah sebelumnya, dengan menggunakan diagram batang yang terkelompok agar dapat diidentifikasi pola distribusi masing-masing kelompok.
barplot(counts,
main="Bar Plot Terkelompok",
xlab="Intervensi", ylab="Frekuensi",
col=c("red", "yellow", "green"),
legend=rownames(counts), beside=TRUE)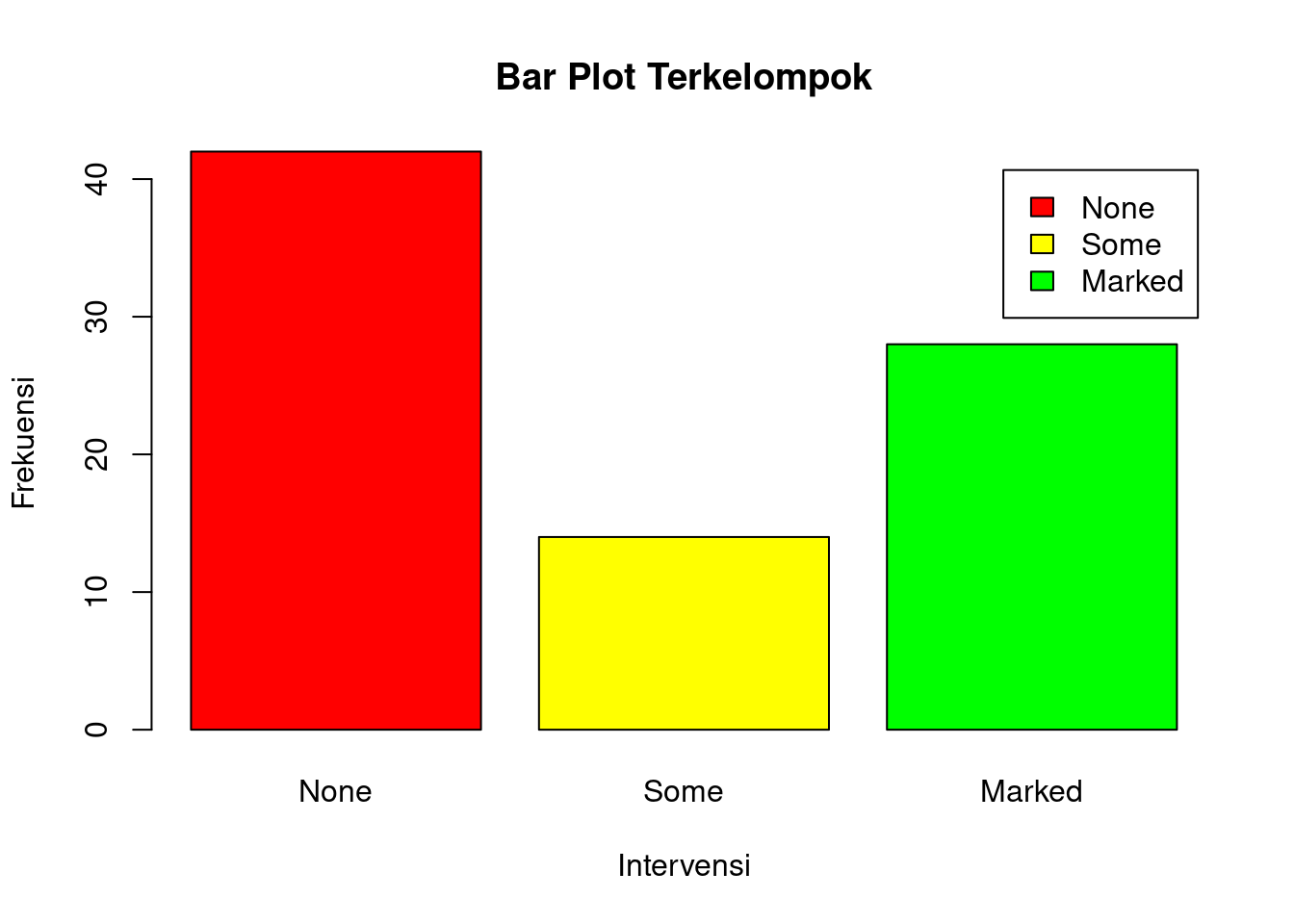
ggplot(cabbage_exp, aes(x=Date, y=Weight, fill=Cultivar, order=desc(Cultivar))) +
geom_bar(stat="identity")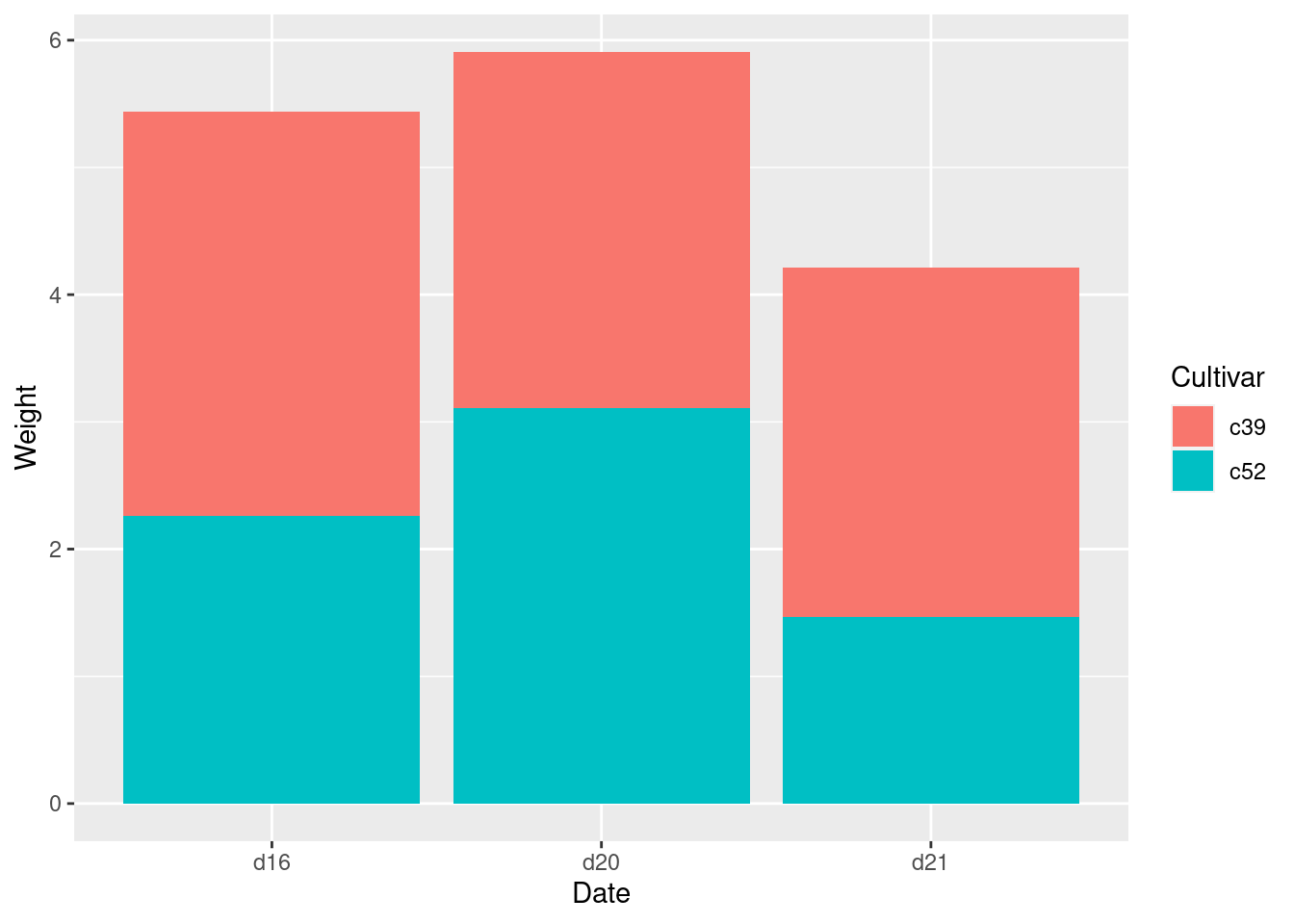
5.3 Histogram
Histogram adalah representasi grafis dari distribusi data numerik. Grafik ini adalah perkiraan distribusi probabilitas dari variabel kontinu atau variabel kuantitatif. Untuk membuat histogram, langkah pertama adalah membagi seluruh rentang nilai menjadi serangkaian interval kemudian menghitung berapa banyak nilai yang dikelompokkan ke dalam setiap interval.
Berikut ini adalah kode R untuk membuat sebuah histogram.
ggplot(mtcars, aes(x=mpg)) + geom_histogram(binwidth=4)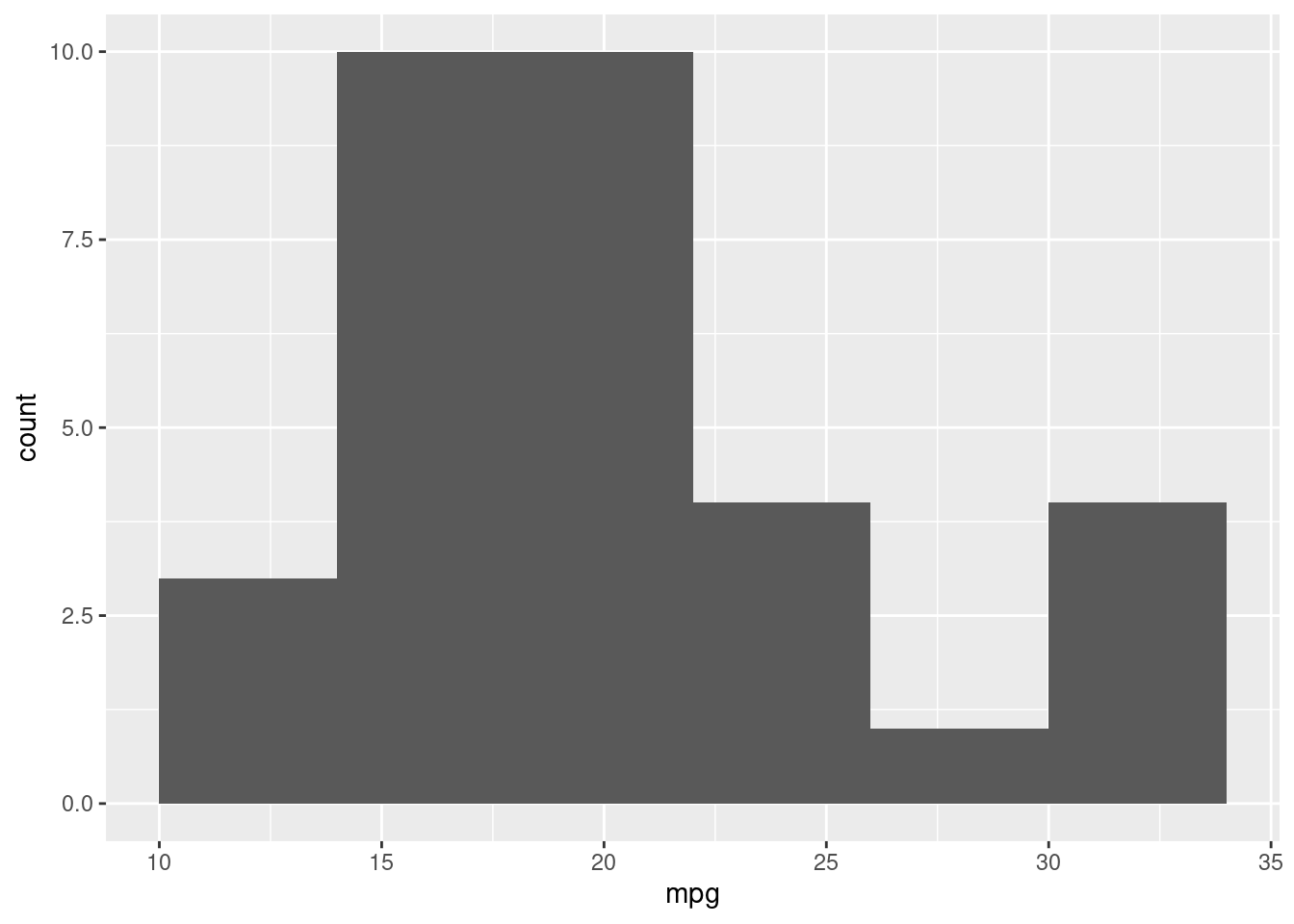
Histogram di atas menggambarkan interval penggunaan bahan bakar dengan satuan miles per gallon dan banyaknya mobil. Nilai tersebut menunjukkan mobil dengan konsumsi bahan bakar tertentu dan berjumlah tertentu.
Histogram dapat juga digambar dengan disertai kurva normal yang dapat membantu untuk memahami secara cepat kurva seperti apa yang akan dihasilkan. Berikut ini adalah contoh kurva normal yang dihasilkan dari dataset mtcars dan variabel mpg.
x <- mtcars$mpg
h<-hist(x, breaks=10, col="red", xlab="Rasio konsumsi BBM",
main="Histogram dengan kurva normal")
xfit<-seq(min(x),max(x),length=40)
yfit<-dnorm(xfit,mean=mean(x),sd=sd(x))
yfit <- yfit*diff(h$mids[1:2])*length(x)
lines(xfit, yfit, col="blue", lwd=2)
5.4 Kernel density
Kernel density adalah cara non-parametrik untuk memperkirakan fungsi kepadatan probabilitas dari variabel acak. Estimasi kernel density adalah proses penghalusan tentang populasi yang dibuat berdasarkan data sampel yang terbatas. Kernel density berguna untuk mengetahui distribusi data yang bersifat kontinu.
Perintah qplot merupakan perintah generik untuk membuat sebuah plot. Setelah itu, depth disebutkan untuk untuk menyebutkan variabel yang digunakan dalam pembuatan plot. Dataset yang digunakan adalah diamonds dengan perintah geom=density untuk memilih fitur spesifik yang akan digambar adalah kernel density.
qplot(depth, data=diamonds, geom="density", xlim = c(54, 70))Warning: `qplot()` was deprecated in ggplot2 3.4.0.Warning: Removed 38 rows containing non-finite values (`stat_density()`).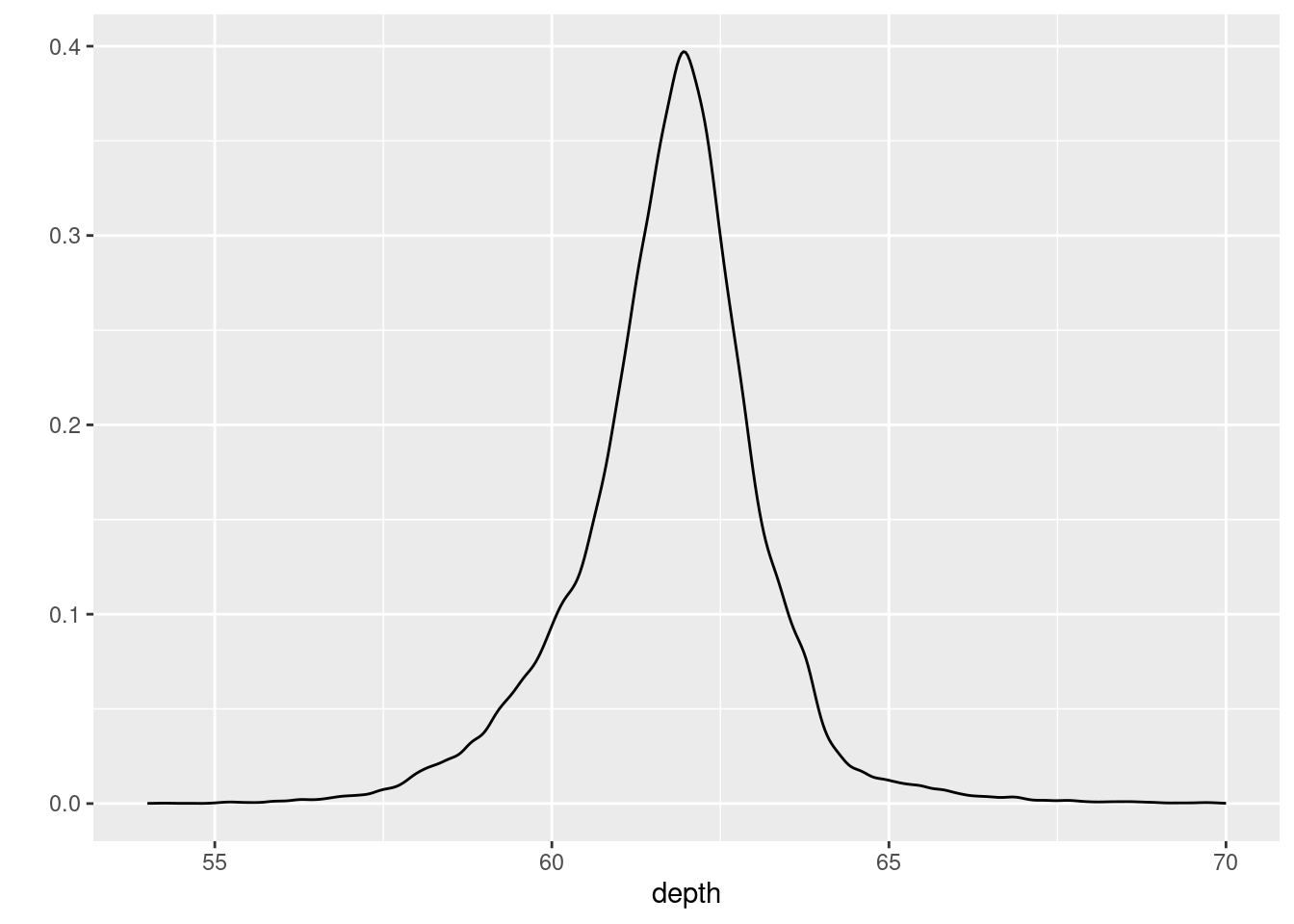
Kernel density yang dihasilkan berasal dari perhitungan variabel depth pada dataset diamonds yang menunjukkan penghalusan distribusi data yang berkisar dari poin 54 sampai 70.
d <- density(mtcars$mpg) # returns the density data
plot(d) # plots the results 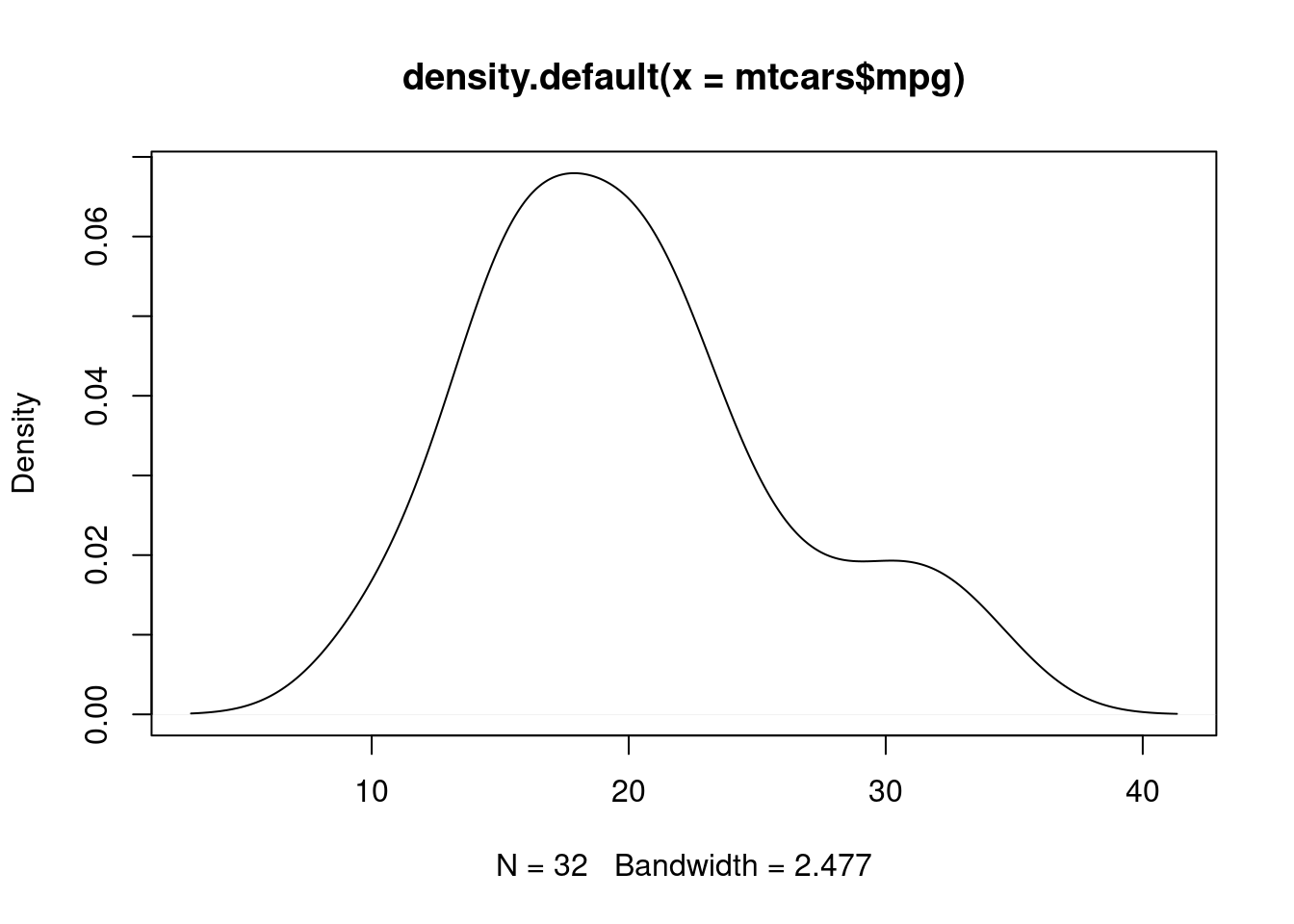
Alternatif lain untuk membuat plot kernel density yaitu dengan memberi perintah density dan menyebutkan dataset dan variabel apa yang akan dituju, dalam hal ini adalah variabel mtcaras dengan dataset mpg.